Python爬虫 bilibili弹幕爬取

工作原理b站是提供弹幕接口的,所以我们的整体操作进行如下:到B站获取cid将cid与网站固定格式进行链接用python请求网页进行简单的单词处理生成词云接下来我们就按照刚才说的顺序进行详细解释操作顺序1.到B站获取cid首先点进一个视频网页,点击F12-network获取监测页面,然后一定要点击播放视频,我们就会在监测页面中看到一个叫heartbeat的XHR脚本,点开任意一个即可。
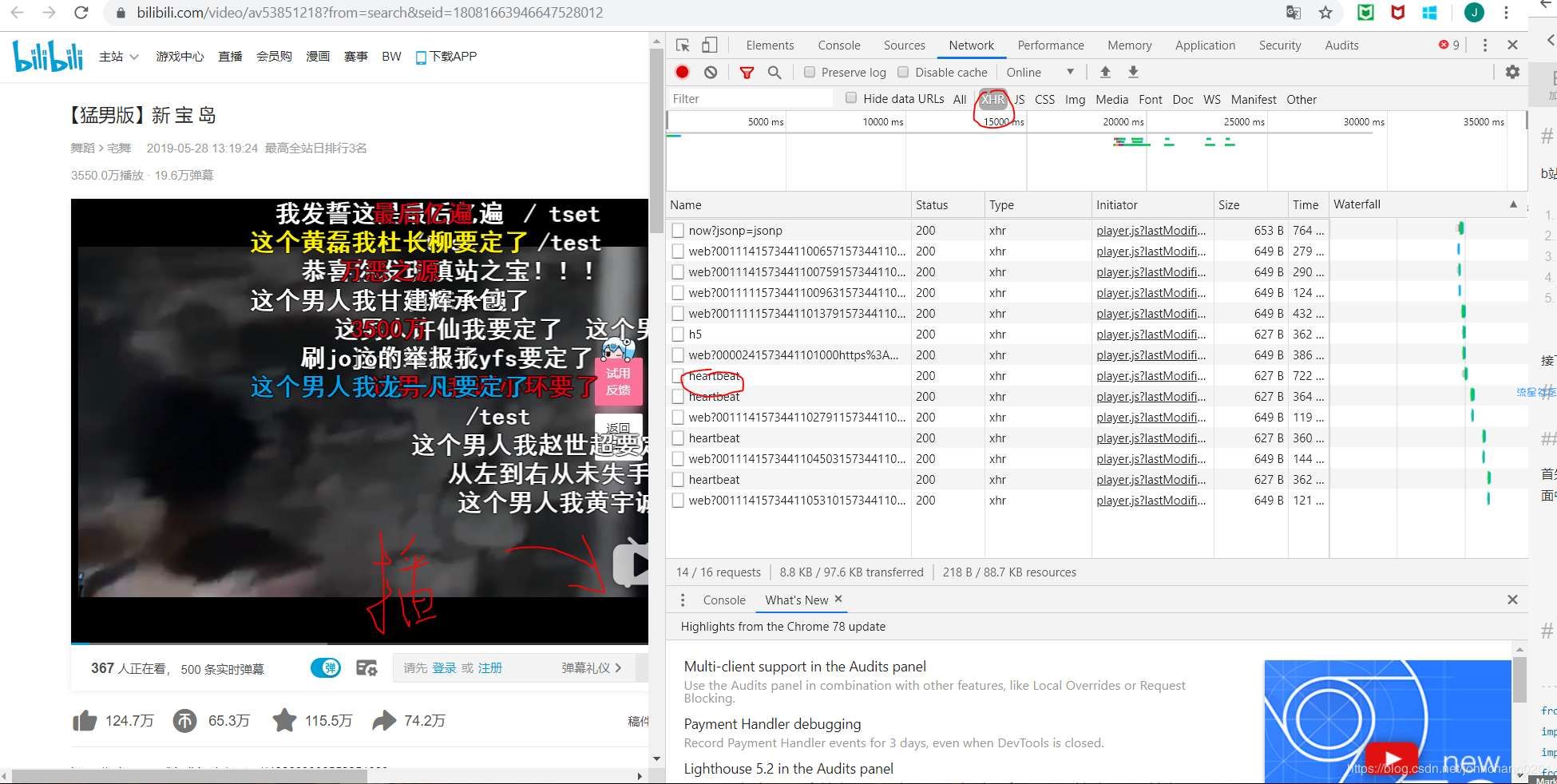
进入页面点击之后我们需要看Headers,里边包括了我们想知道的信息。往下滚动就会发现cid,这个id是唯一的,也就是说下次抓取的时候还可以用这个id。获取cid2.将cid与网站固定格式进行链接我们拿到cid之后就可以去检查一下是否可以获取弹幕了。获取的固定xml格式是:https://comment.bilibili.com/视频的cid.xml例如在这里我们的页面就是:'https://comment.bilibili.com/94198756.xml'1我们把这个链接用网页的方式打开,就能看到如下内容:弹幕内容这样我们就确定可以爬取了。
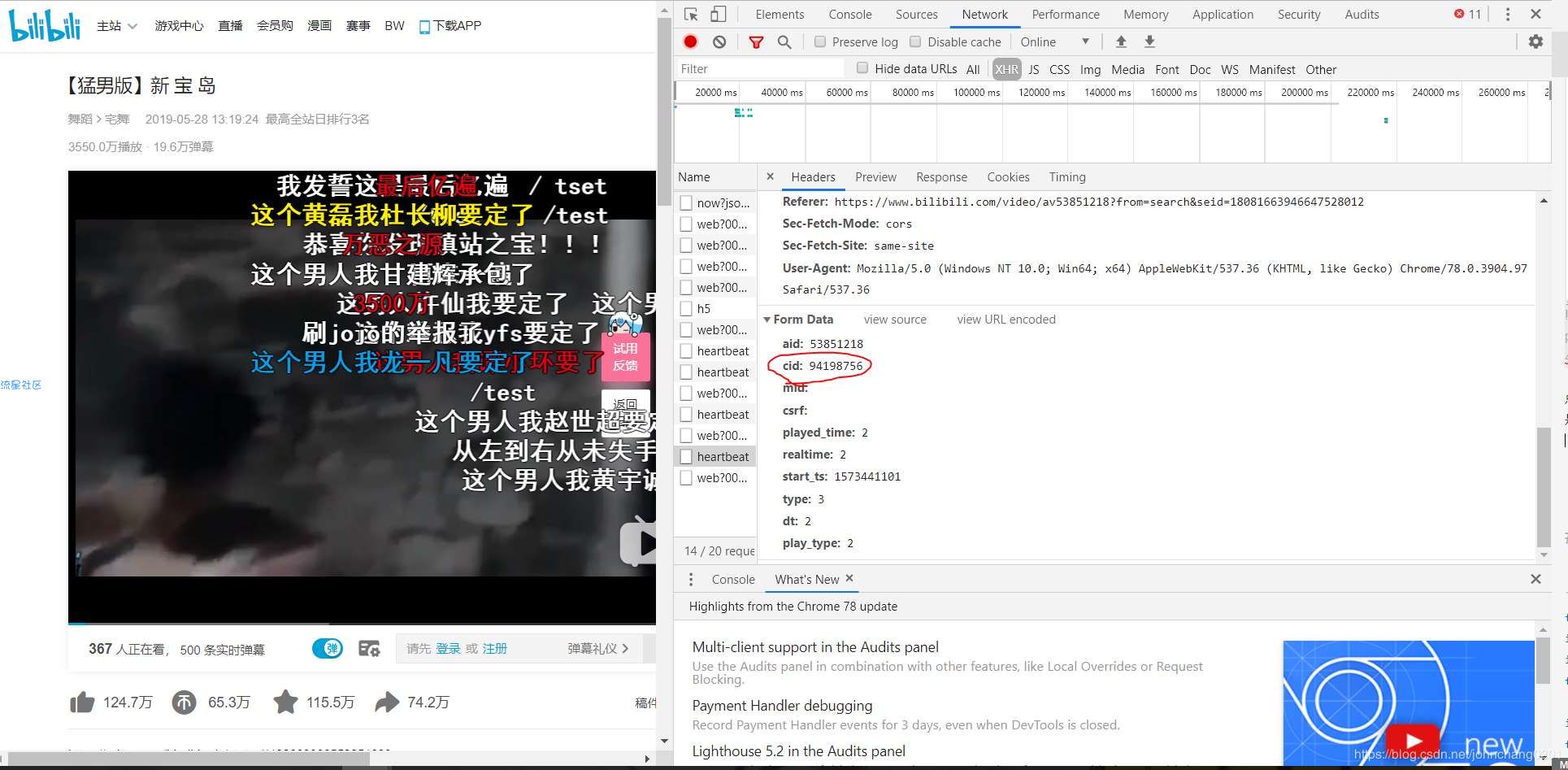
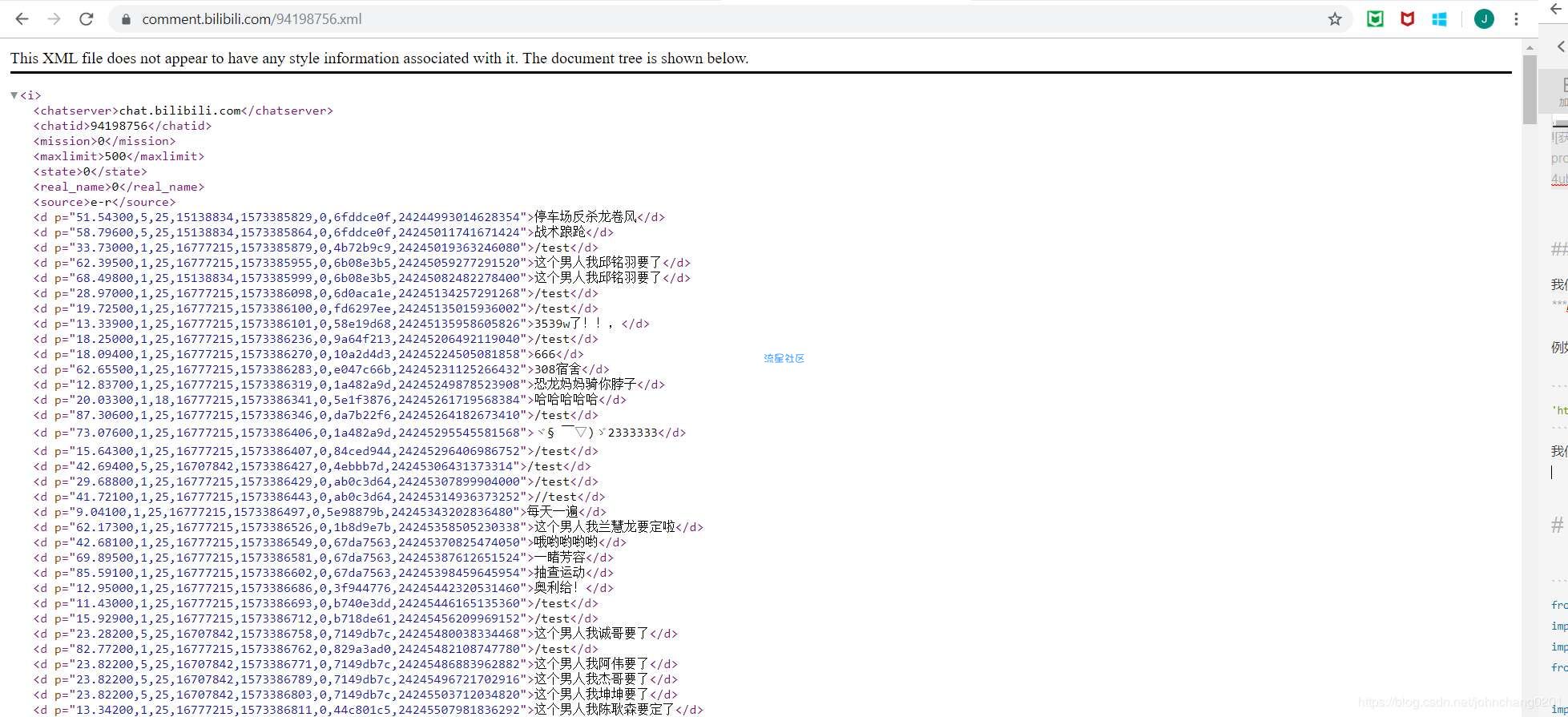
3.用python请求网页因为是开源的,我们也不需要设置代理agent什么的,直接获取就行import requestsfrom bs4 import BeautifulSoupurl= 'https://comment.bilibili.com/94198756.xml'request = requests.get(url)#获取页面request.encoding='utf8'#因为是中文,我们需要进行转码,否则出来的都是unicode通过之前的网页查看,我们发现弹幕的XML规律如下:

comments_clean = [element for element in comments_clean if element not in useless_words]#去掉不想要的字符 进行完上述处理之后,我们就可以进行词云的制作了。不过在制作之前,还是让我们简单的看一下词频。(不是最终的,因为一会要把句子里的词分开)import pandas as pdcipin = pd.DataFrame({'danmu':comments_clean})cipin['danmu'].value_counts()(4)分词在这里我们把刚才得到的弹幕用jieba库进行分词danmustr = ''.join(element for element in comments_clean)#把所有的弹幕都合并成一个字符串

2条回复 |
最后回复于2019-11-16
我弧你你就得忍着
回复列表
-

内容加载中...
说点什么...
[挠墙]忍忍忍
回复列表
-
内容加载中...
说点什么...
 返回首页
返回首页
 编程源码
编程源码


