爬虫相关

网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。


250条回复 |
最后回复于2019-12-12
当然,大部分网站不是你拷贝一下cURL链接,改改其中参数就可以拿到数据的,接下来我们做更深层次的分析,就需要用到Postman“大杀器”了。为什么是“大杀器”呢?因为它着实强大。配合cURL,我们可以将请求的内容直接移植过来,然后对其中的请求进行改造,勾选即可选择我们想要的内容参数,非常优雅
回复列表
-

内容加载中...
说点什么...
5、Online JavaScript Beautifier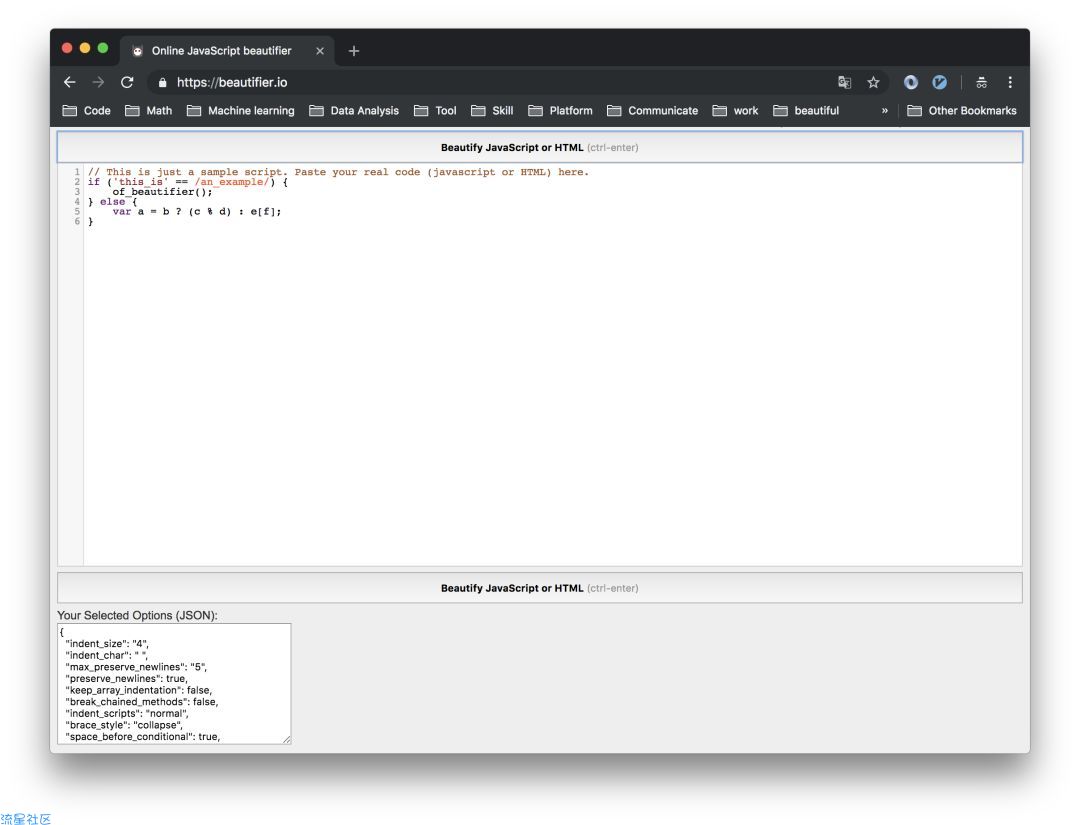
回复列表
-
内容加载中...
说点什么...
用了以上的工具,你基本可以解决大部分网站了,算是一个合格的初级爬虫工程师了。这个时候,我们想要进阶就需要面对更复杂的网站爬虫了,这个阶段,你不仅要会后端的知识,还需要了解一些前端的知识,因为很多网站的反爬措施是放在前端的。你需要提取对方站点的js信息,并需要理解和逆向回去,原生的js代码一般不易于阅读,这时,就要它来帮你格式化吧
回复列表
-
内容加载中...
说点什么...
6、EditThisCookie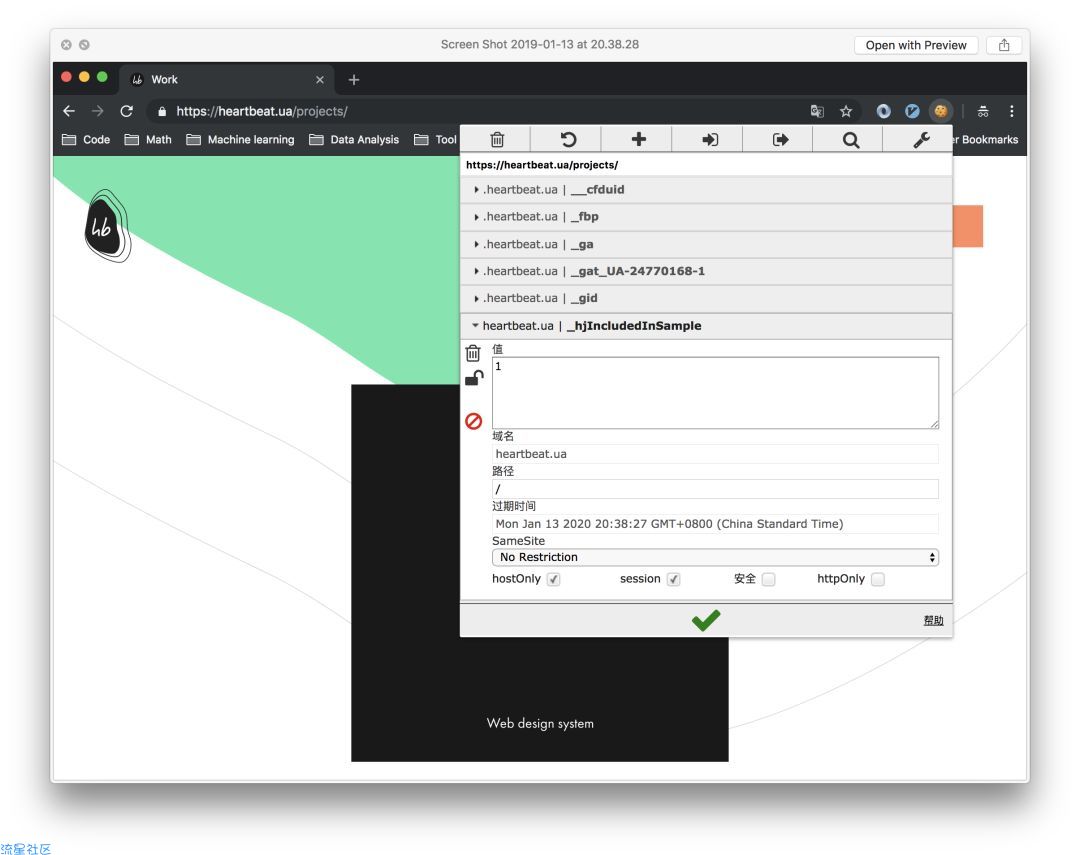
回复列表
-
内容加载中...
说点什么...
爬虫和反爬虫就是一场没有硝烟的拉锯战,你永远不知道对方会给你埋哪些坑,比如对Cookies动手脚。这个时候你就需要它来辅助你分析,通过Chrome安装EditThisCookie插件后,我们可以通过点击右上角小图标,再对Cookies里的信息进行增删改查操作,大大提高对Cookies信息的模拟
回复列表
-
内容加载中...
说点什么...
第三步:开始设计爬虫的架构
回复列表
-
内容加载中...
说点什么...
7、Sketch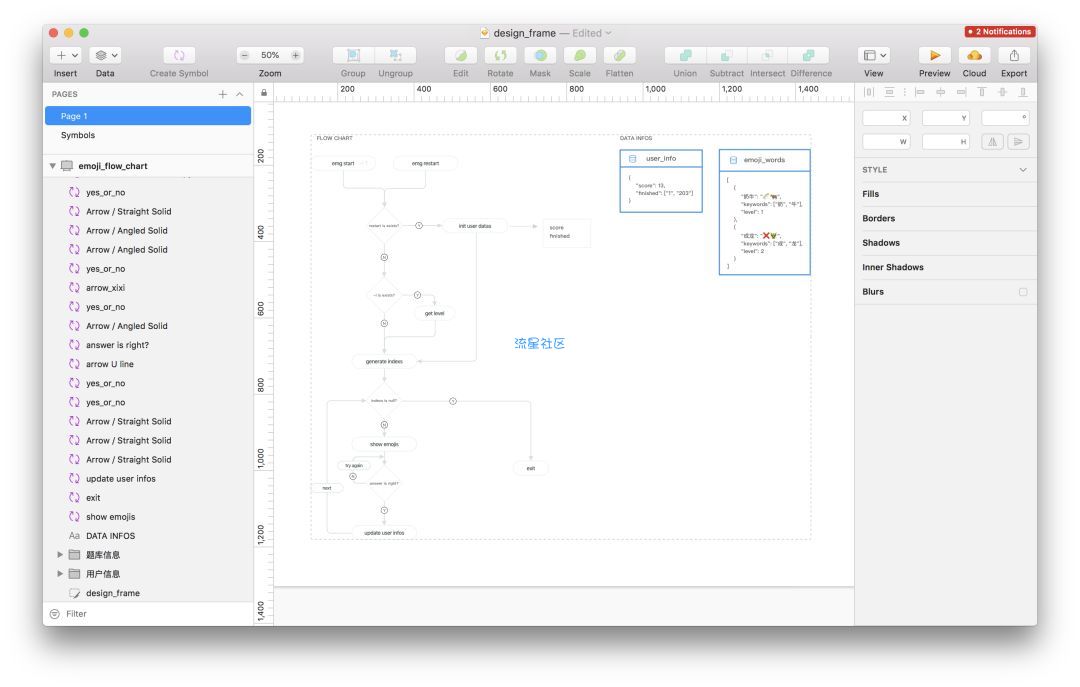
回复列表
-
内容加载中...
说点什么...
当我们已经确定能爬取之后,我们不应该着急动手写爬虫。而是应该着手设计爬虫的结构。按照业务的需求,我们可以做一下简单的爬取分析,这有助于我们之后开发的效率,所谓磨刀不误砍柴工就是这个道理。比如可以考虑下,是搜索爬取还是遍历爬取?采用BFS还是DFS?并发的请求数大概多少?考虑一下这些问题后,我们可以通过Sketch来画一下简单的架构图
回复列表
-
内容加载中...
说点什么...
同类工具:Illustrator、 Photoshop
回复列表
-
内容加载中...
说点什么...
最后:开始愉快的爬虫之旅吧
回复列表
-
内容加载中...
说点什么...
 返回首页
返回首页
 编程源码
编程源码


