【python】爬虫实战系列!爬视频网2

【前言】
在爬一个网站之前,我们得知道要爬的内容在哪?怎么获取它,然后爬它,这非常的重要!
【工具】
1、chrome 浏览
2、开发者模式
【实战】
版面太小, 更新!


在爬一个网站之前,我们得知道要爬的内容在哪?怎么获取它,然后爬它,这非常的重要!
【工具】
1、chrome 浏览
2、开发者模式
【实战】
版面太小, 更新!
40条回复 |
最后回复于2020-2-10
来我们团队吧
回复列表
-

内容加载中...
说点什么...
options.add_argument('--headless') # 设置无头模式 ,JS界面是不能用request库来爬取的,但是它可以用到一个测试框架selenium,这是调用了真实的浏览器来访问网页以达到爬取目的,但爬虫是不需要界面的因为那样很麻烦!所以我们需要一个没有界面的浏览器
回复列表
-
内容加载中...
说点什么...
options.add_argument('disable-infobars') # 隐藏"Chrome正在受到自动软件的控制 这个我就图片给你们看下,它隐藏了什么东西。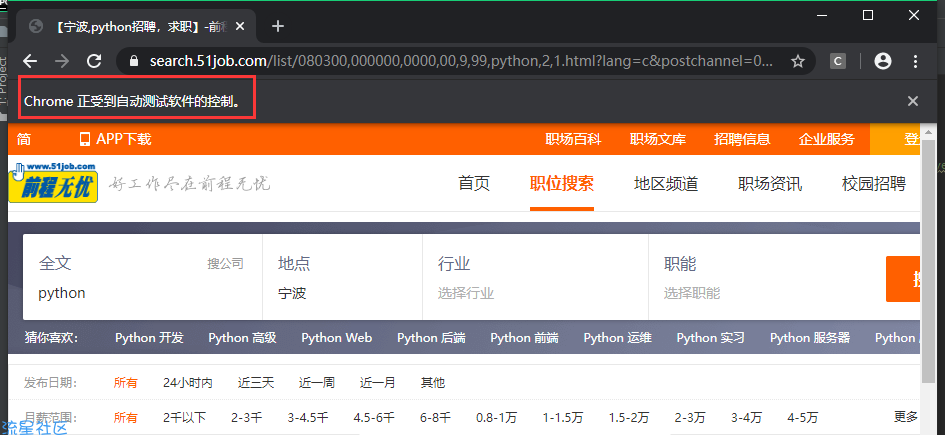
回复列表
-
内容加载中...
说点什么...
user_ag = (
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36') # 设置头部 ,这是反反爬里最常用但也最实用的一步,如果不实用它,爬虫就会像瓜皮一样告诉网站我是一个可恶的臭虫,我要来搞搞你了,所以务必加上它,它模拟了浏览器的访问
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36') # 设置头部 ,这是反反爬里最常用但也最实用的一步,如果不实用它,爬虫就会像瓜皮一样告诉网站我是一个可恶的臭虫,我要来搞搞你了,所以务必加上它,它模拟了浏览器的访问
回复列表
-
内容加载中...
说点什么...
driver.get(url) 只有这行代码是正式访问网站,开启爬虫第一步
回复列表
-
内容加载中...
说点什么...
html = driver.page_source 取得网站内容,并保存在变量:html里面
回复列表
-
内容加载中...
说点什么...
driver.quit() 用于结束进程 ,关闭所有窗口。把无头浏览器给关闭掉,不能它没有界面就不去管他,这样你的电脑早晚会内存爆炸
回复列表
-
内容加载中...
说点什么...
return html 返回内容,以便其他函数进行读取分析
回复列表
-
内容加载中...
说点什么...
好啦今天就先到这啦
回复列表
-
内容加载中...
说点什么...
好的呀
回复列表
-
内容加载中...
说点什么...
 返回首页
返回首页
 编程源码
编程源码


