python爬虫实战之爬视频网4

python爬虫实战!全是干货!进来看~
【前言】
上面帖子分析了视频网站板块下视频分组URL,这次我们要爬视频!
【工具】
1、python 3X
2、pycharm
3、Sublime
4、chrome
5、notepad++
【实现】
我们需要找到视频真正的播放地址即m3u8链接,这个文件储存的是视频的TS链接,我们要提取出他来,并且下载到本地文件,因模板原因,我会把提取链接跟下载分成两个帖子,下面看代码。
【代码】
try:
lst = []
html = getnumberbuname(url)
restr = r'''width="100%" height="480" src="(.*)" frameborder'''
regex = re.compile(restr, re.IGNORECASE)
mylist = regex.findall(html)
text = mylist[0].split('=')
tet = text[1].rsplit('/', 1)[:1]
print(tet)
#输出信息,用以查看是否正常获取
urls = tet[0] + '/1000k/hls/index.m3u8'
print('获取到m3u8下载链接:', urls)
txt = requests.get(urls).text
res = '''(.*.ts)\n'''
#获取M3U8里的TS链接
reg = re.compile(res, re.IGNORECASE)
myl = reg.findall(txt)
#取出结果
path = 'd:/视频/电影/' + rod + '/'
#文件保存路径
print('文件保存在:', path)
except:
return '解析错误'
ps:我删除了一部分代码,那是用来下载二进制文件到我们自己硬盘上的,版面太小放不下。
【结束语】
下载电影板块的视频的代码就这么长,是不是很简单呢?对它实现的非常简单,首先调用一下之前的函数,获取到网页的内容,然后用正则直接取出我们所M3U8链接,再去获取M3U8里的TS链接,然后用二进制的方法下载下来保存到我们电脑上,步骤就这些,很简单把,一起来实现下它。
PS:代码部分我会放在稍后的下载链接里
【下载地址】
蓝奏云下载:
感觉本文不错的就点个赞,加个关注!每天晚上都会有更新哦~~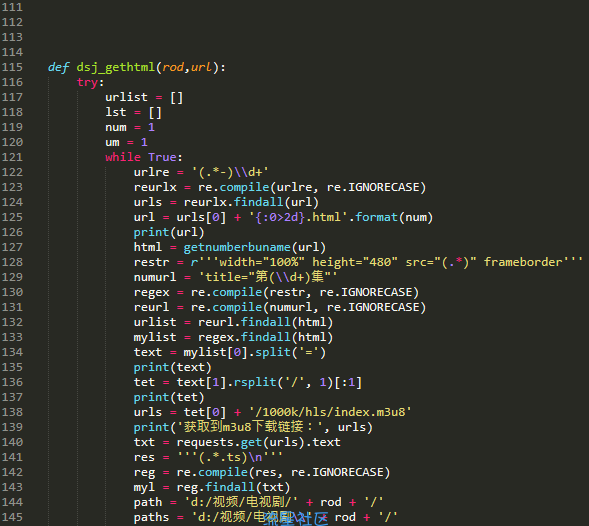

【前言】
上面帖子分析了视频网站板块下视频分组URL,这次我们要爬视频!
【工具】
1、python 3X
2、pycharm
3、Sublime
4、chrome
5、notepad++
【实现】
我们需要找到视频真正的播放地址即m3u8链接,这个文件储存的是视频的TS链接,我们要提取出他来,并且下载到本地文件,因模板原因,我会把提取链接跟下载分成两个帖子,下面看代码。
【代码】
try:
lst = []
html = getnumberbuname(url)
restr = r'''width="100%" height="480" src="(.*)" frameborder'''
regex = re.compile(restr, re.IGNORECASE)
mylist = regex.findall(html)
text = mylist[0].split('=')
tet = text[1].rsplit('/', 1)[:1]
print(tet)
#输出信息,用以查看是否正常获取
urls = tet[0] + '/1000k/hls/index.m3u8'
print('获取到m3u8下载链接:', urls)
txt = requests.get(urls).text
res = '''(.*.ts)\n'''
#获取M3U8里的TS链接
reg = re.compile(res, re.IGNORECASE)
myl = reg.findall(txt)
#取出结果
path = 'd:/视频/电影/' + rod + '/'
#文件保存路径
print('文件保存在:', path)
except:
return '解析错误'
ps:我删除了一部分代码,那是用来下载二进制文件到我们自己硬盘上的,版面太小放不下。
【结束语】
下载电影板块的视频的代码就这么长,是不是很简单呢?对它实现的非常简单,首先调用一下之前的函数,获取到网页的内容,然后用正则直接取出我们所M3U8链接,再去获取M3U8里的TS链接,然后用二进制的方法下载下来保存到我们电脑上,步骤就这些,很简单把,一起来实现下它。
PS:代码部分我会放在稍后的下载链接里
【下载地址】
蓝奏云下载:
感觉本文不错的就点个赞,加个关注!每天晚上都会有更新哦~~
7条回复 |
最后回复于2020-2-9
第一
回复列表
-

内容加载中...
说点什么...
看座
回复列表
-
内容加载中...
说点什么...
没有胡楼了
回复列表
-
内容加载中...
说点什么...
?。。。。。。。
回复列表
-
内容加载中...
说点什么...
本版块最新版规规定发帖主题必须带有相关图片,无相关图片当做无图处理,请楼主尽快补图,长时间未补图会锁帖处理
回复列表
-
内容加载中...
说点什么...
诺诺诺~~~
回复列表
-
内容加载中...
说点什么...
楼主是个大方人
回复列表
-
内容加载中...
说点什么...
 返回首页
返回首页
 编程源码
编程源码


