爬虫实战,从零开始爬取图片网站使用JAVA

感谢小星星提供这么好的目标素材#【悬赏100星币】获取网站图片#
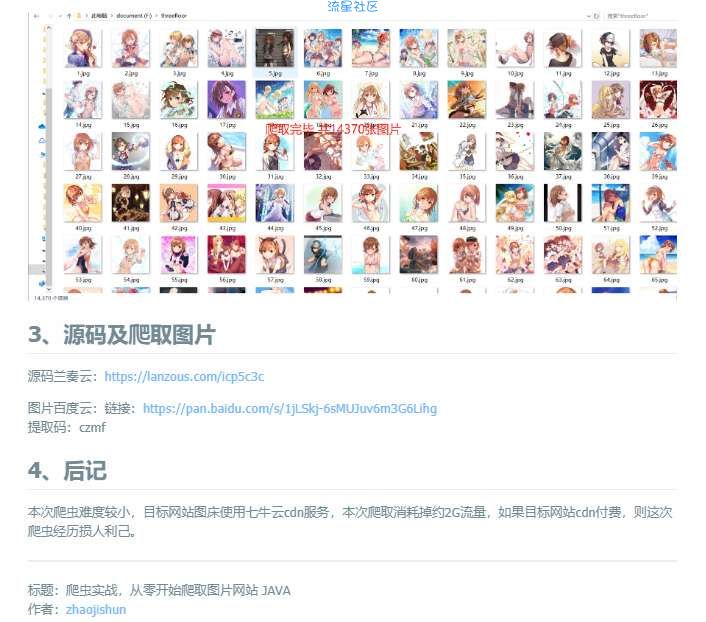
本次爬取图片一万多张,约2个G
0,前言
今日正好没事干,看到有人悬赏,正好练手
1,分析
本次目标网站为bilibili.cx
网站为传统型网站,一页显示60张图片,分页使用get请求,每点击下一页page字段加1
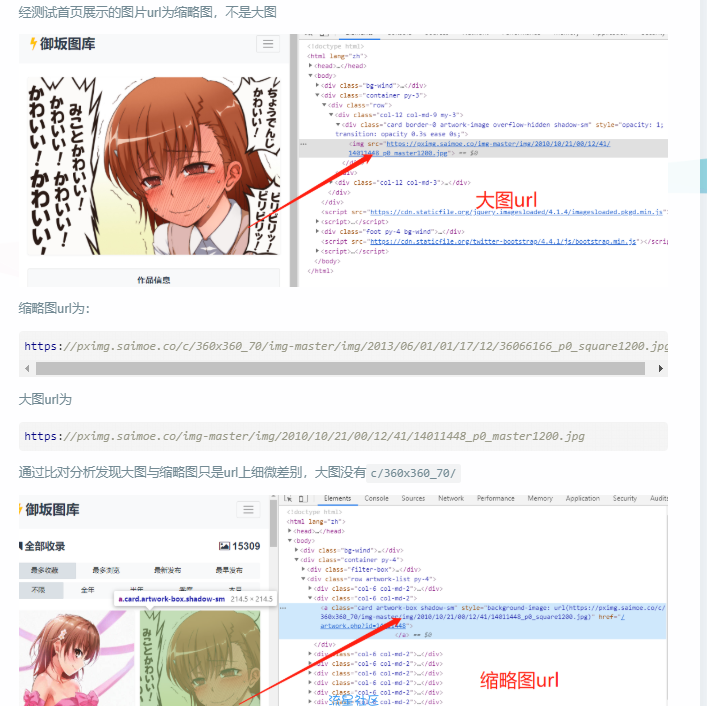
经测试首页展示的图片url为缩略图,不是大图
通过比对分析发现大图与缩略图只是url上细微差别,大图没有c/360x360_70/
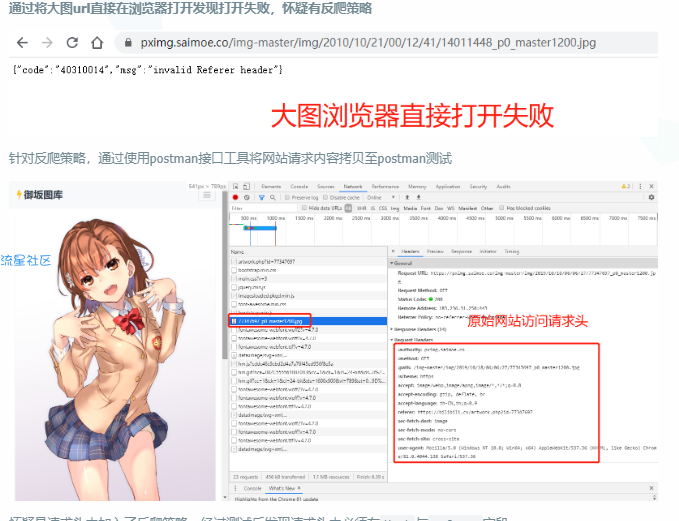
通过将大图url直接在浏览器打开发现打开失败,怀疑有反爬策略
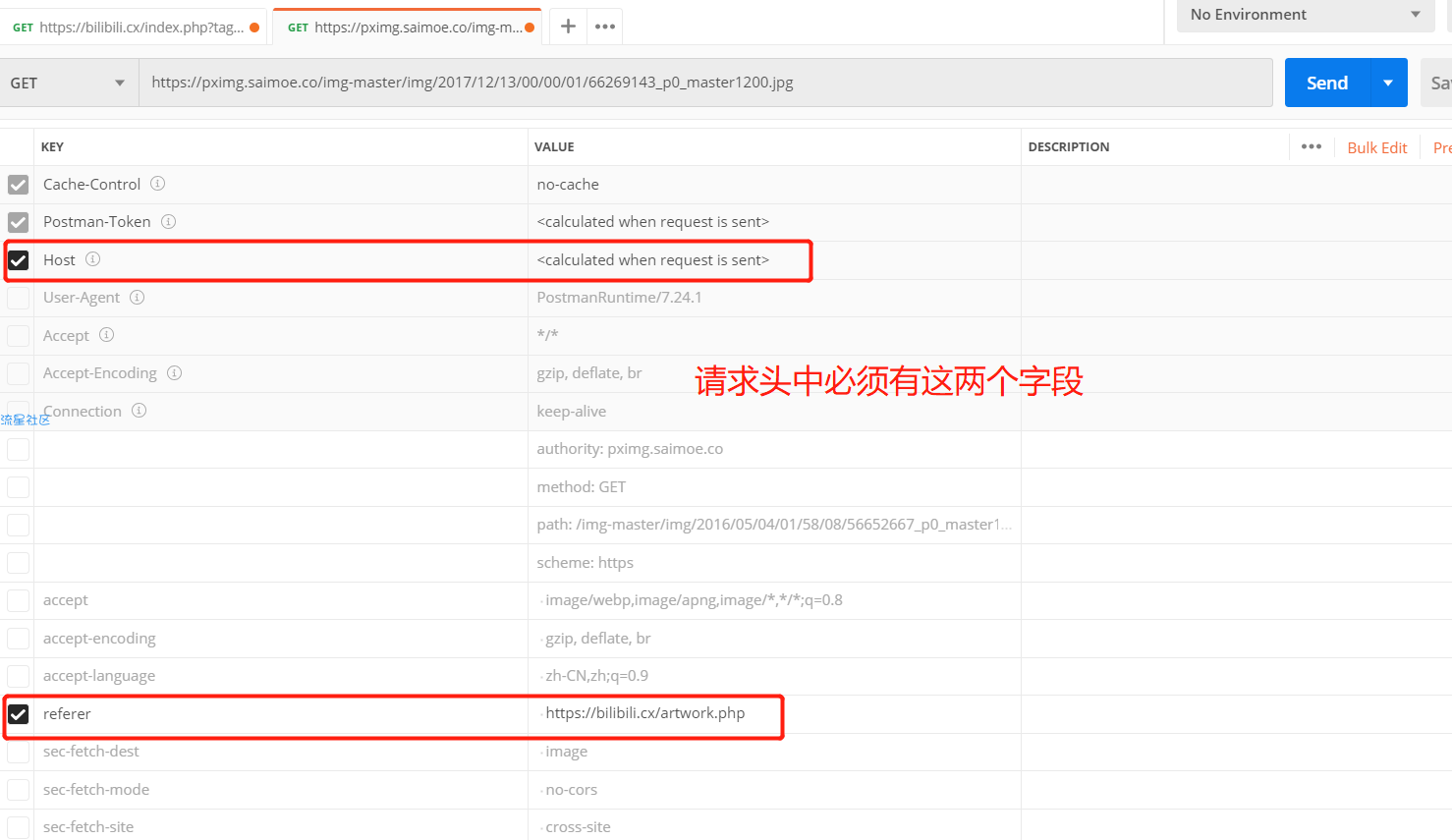
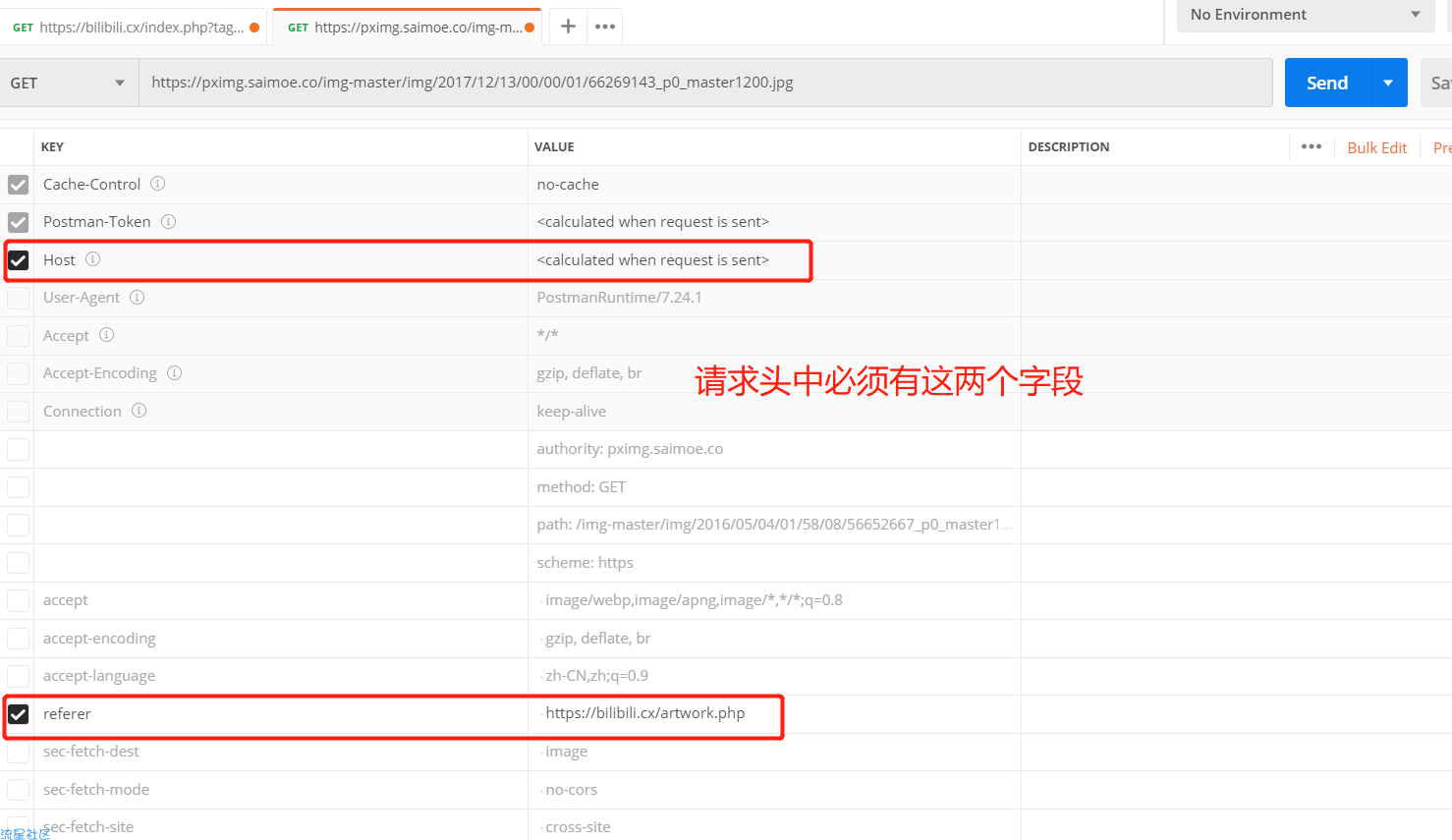
针对反爬策略,通过使用postman接口工具将网站请求内容拷贝至postman测试
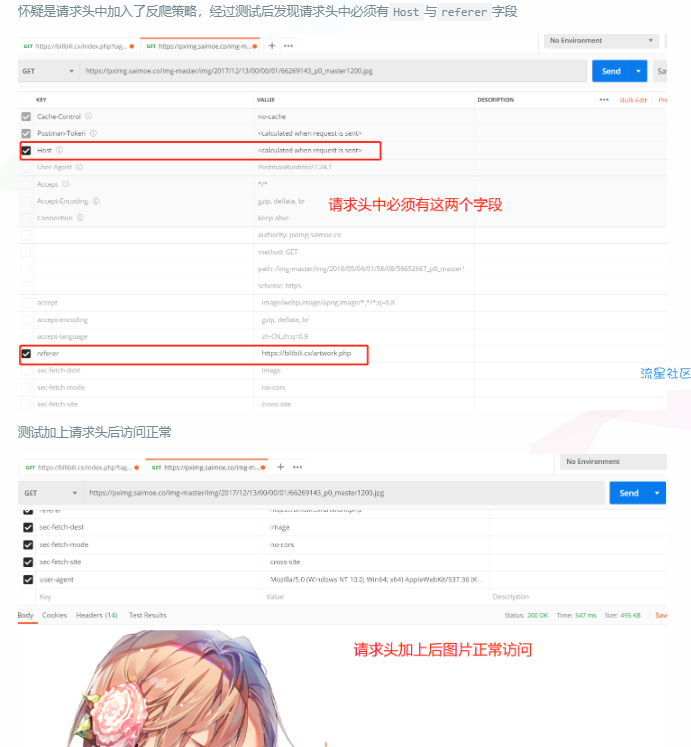
怀疑是请求头中加入了反爬策略,经过测试后发现请求头中必须有Host与referer字段
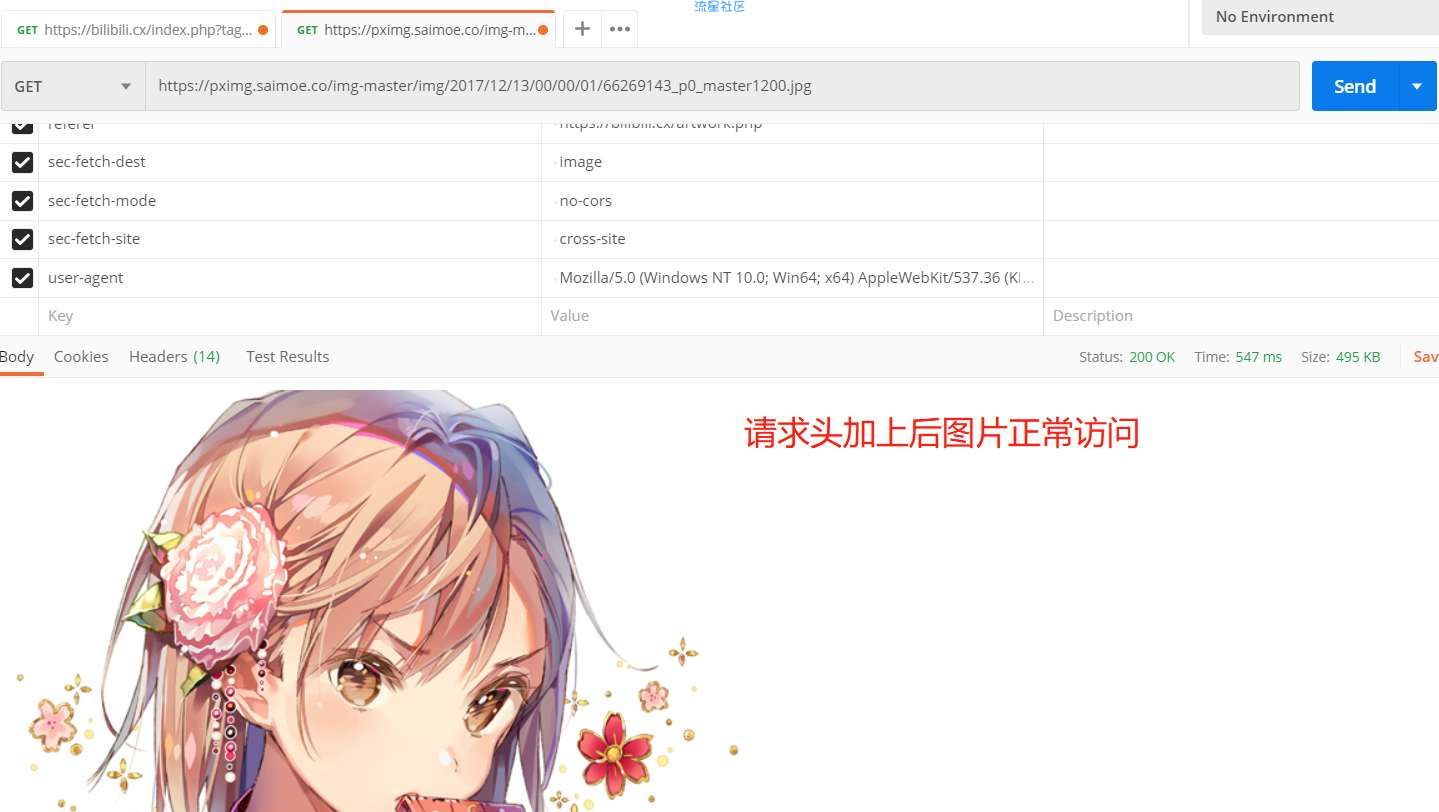
测试加上请求头后访问正常
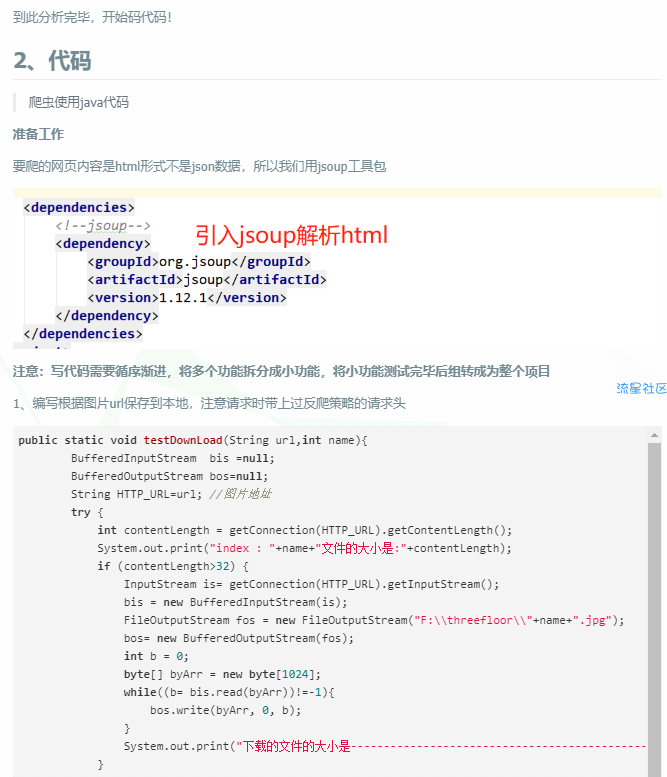
到此分析完毕,开始码代码!
2、代码
爬虫使用java代码
准备工作
要爬的网页内容是html形式不是json数据,所以我们用jsoup工具包
注意:写代码需要循序渐进,将多个功能拆分成小功能,将小功能测试完毕后组转成为整个项目
编写根据图片url保存到本地,注意请求时带上过反爬策略的请求头
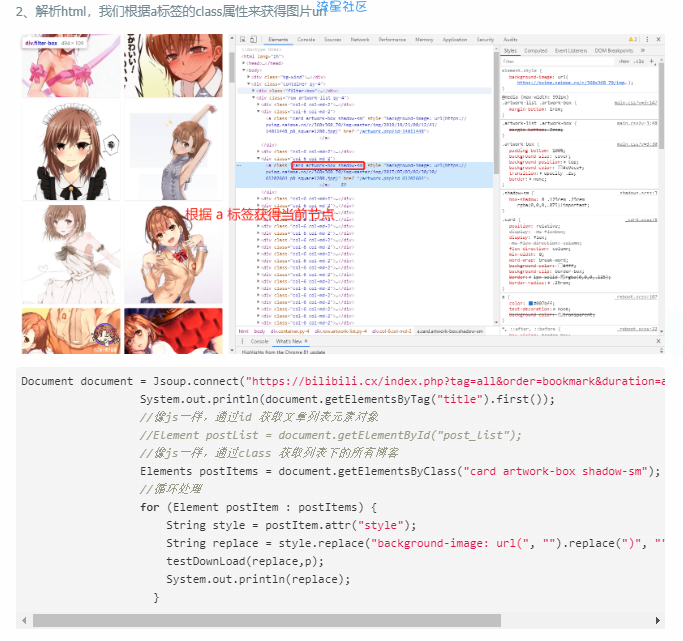
解析html,我们根据a标签的class属性来获得图片url
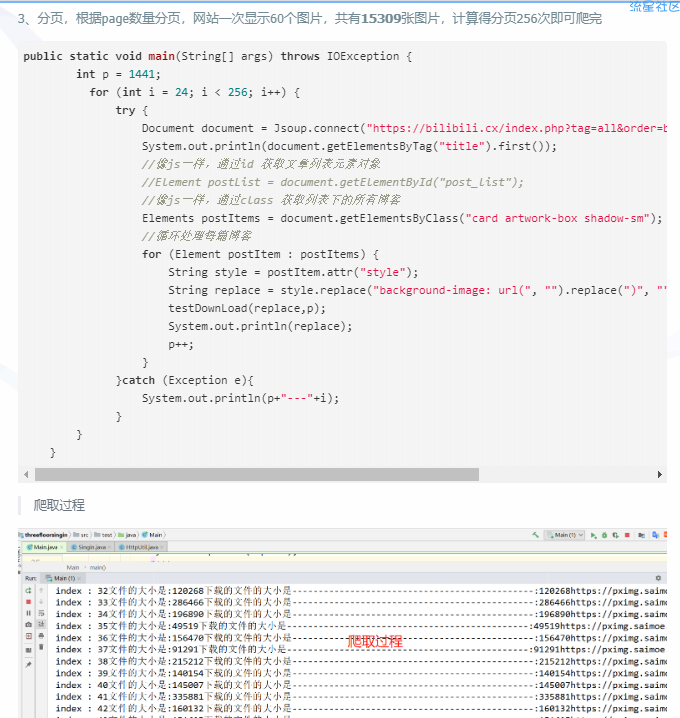
分页,根据page数量分页,网站一次显示60个图片,共有15309张图片,计算得分页256次即可爬完
3、成果
源码兰奏云:https://lanzoui.com/icp5c3c
爬取的图片百度云:链接:https://pan.baidu.com/s/1jLSkj-6sMUJuv6m3G6Lihg
提取码:czmf
图文blog:http://blog.zhaojishun.cn/articles/2020/05/16/1589626238319.html
4、后记
本次爬虫难度较小,目标网站图床使用七牛云cdn服务,本次爬取消耗掉约2G流量,如果目标网站cdn付费,则这次爬虫经历损人利己。
图文图片在下面
楼中我会更新详细细节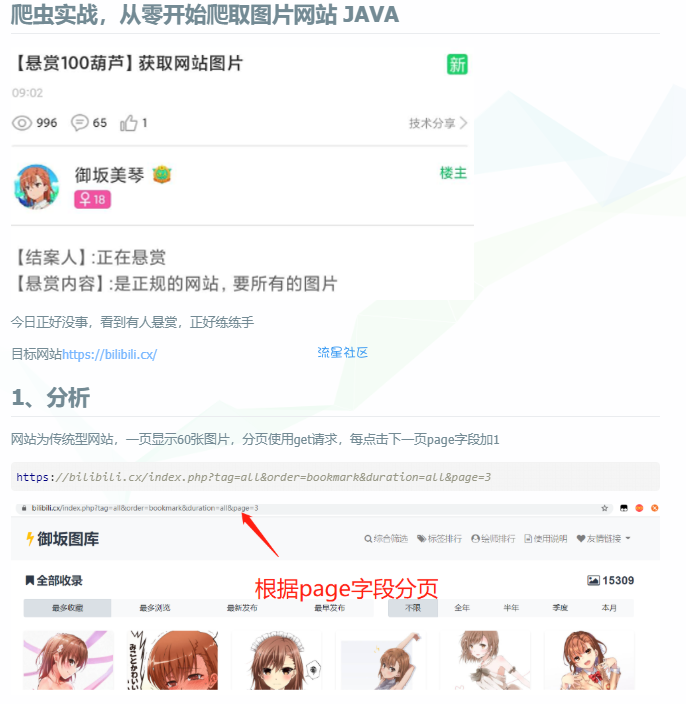
本次爬取图片一万多张,约2个G
0,前言
今日正好没事干,看到有人悬赏,正好练手
1,分析
本次目标网站为bilibili.cx
网站为传统型网站,一页显示60张图片,分页使用get请求,每点击下一页page字段加1
经测试首页展示的图片url为缩略图,不是大图
通过比对分析发现大图与缩略图只是url上细微差别,大图没有c/360x360_70/
通过将大图url直接在浏览器打开发现打开失败,怀疑有反爬策略
针对反爬策略,通过使用postman接口工具将网站请求内容拷贝至postman测试
怀疑是请求头中加入了反爬策略,经过测试后发现请求头中必须有Host与referer字段
测试加上请求头后访问正常
到此分析完毕,开始码代码!
2、代码
爬虫使用java代码
准备工作
要爬的网页内容是html形式不是json数据,所以我们用jsoup工具包
注意:写代码需要循序渐进,将多个功能拆分成小功能,将小功能测试完毕后组转成为整个项目
编写根据图片url保存到本地,注意请求时带上过反爬策略的请求头
解析html,我们根据a标签的class属性来获得图片url
分页,根据page数量分页,网站一次显示60个图片,共有15309张图片,计算得分页256次即可爬完
3、成果
源码兰奏云:https://lanzoui.com/icp5c3c
爬取的图片百度云:链接:https://pan.baidu.com/s/1jLSkj-6sMUJuv6m3G6Lihg
提取码:czmf
图文blog:http://blog.zhaojishun.cn/articles/2020/05/16/1589626238319.html
4、后记
本次爬虫难度较小,目标网站图床使用七牛云cdn服务,本次爬取消耗掉约2G流量,如果目标网站cdn付费,则这次爬虫经历损人利己。
图文图片在下面
楼中我会更新详细细节
20条回复 |
最后回复于2020-5-16
楼更细节:
今日正好没事,看到有人悬赏,正好练练手
目标网站bilibili.cx
今日正好没事,看到有人悬赏,正好练练手
目标网站bilibili.cx
回复列表
-

内容加载中...
说点什么...
1、分析
网站为传统型网站,一页显示60张图片,分页使用get请求,每点击下一页page字段加1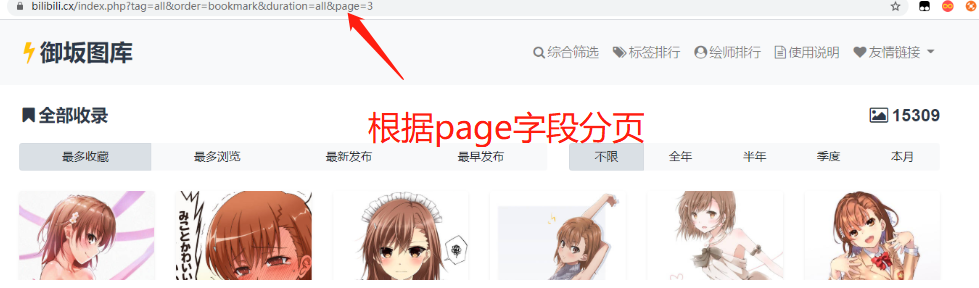
网站为传统型网站,一页显示60张图片,分页使用get请求,每点击下一页page字段加1
回复列表
-
内容加载中...
说点什么...
经测试首页展示的图片url为缩略图,不是大图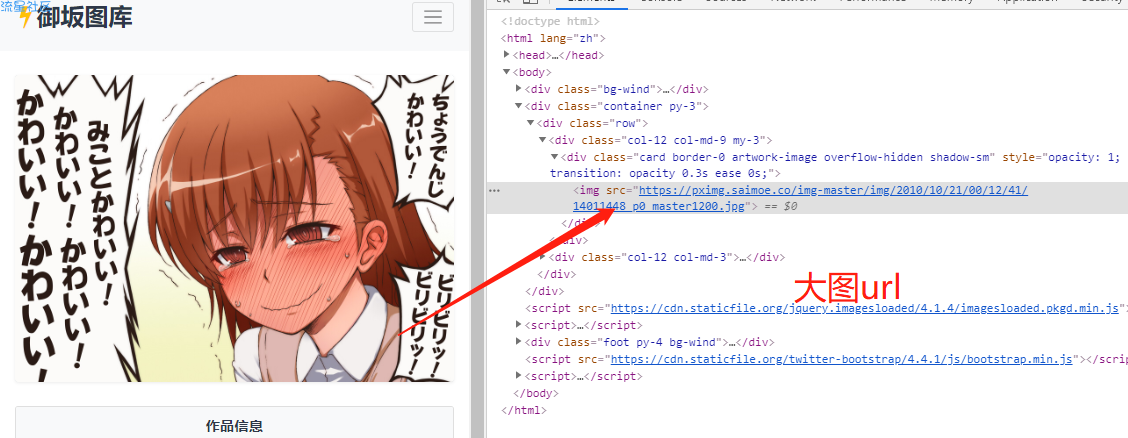
回复列表
-
内容加载中...
说点什么...
吃完饭再更
回复列表
-
内容加载中...
说点什么...
缩略图url为:
https://pximg.saimoe.co/c/360x360_70/img-master/img/2013/06/01/01/17/12/36066166_p0_square1200.jpg
大图url为
https://pximg.saimoe.co/img-master/img/2010/10/21/00/12/41/14011448_p0_master1200.jpg
通过比对分析发现大图与缩略图只是url上细微差别,大图没有c/360x360_70/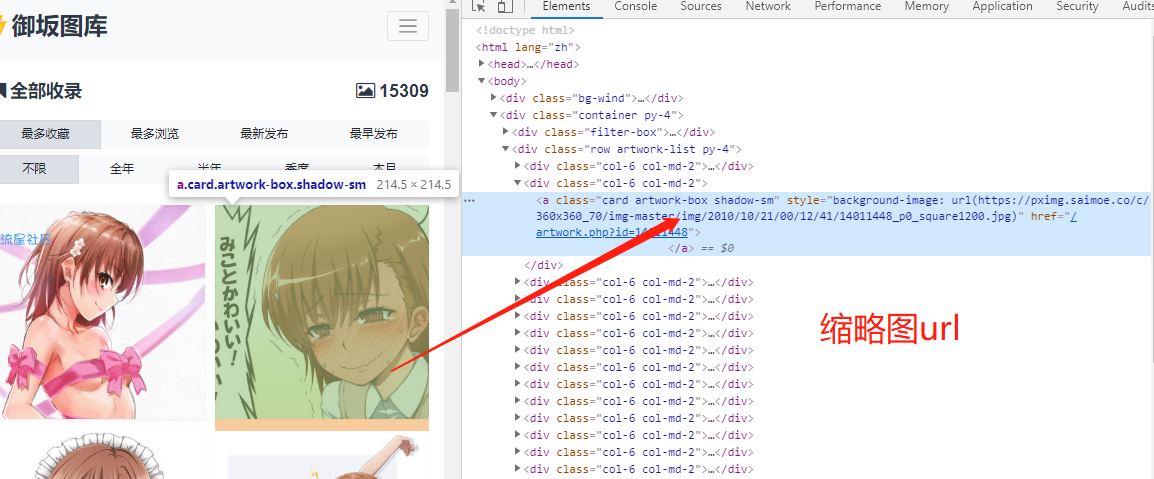
https://pximg.saimoe.co/c/360x360_70/img-master/img/2013/06/01/01/17/12/36066166_p0_square1200.jpg
大图url为
https://pximg.saimoe.co/img-master/img/2010/10/21/00/12/41/14011448_p0_master1200.jpg
通过比对分析发现大图与缩略图只是url上细微差别,大图没有c/360x360_70/
回复列表
-
内容加载中...
说点什么...
通过将大图url直接在浏览器打开发现打开失败,怀疑有反爬策略
回复列表
-
内容加载中...
说点什么...
前排
回复列表
-
内容加载中...
说点什么...
挺眼熟的哈
回复列表
-
内容加载中...
说点什么...
到此分析完毕,开始码代码!
回复列表
-
内容加载中...
说点什么...
针对反爬策略,通过使用postman接口工具将网站请求内容拷贝至postman测试
怀疑是请求头中加入了反爬策略,经过测试后发现请求头中必须有Host与referer字段
测试加上请求头后访问正常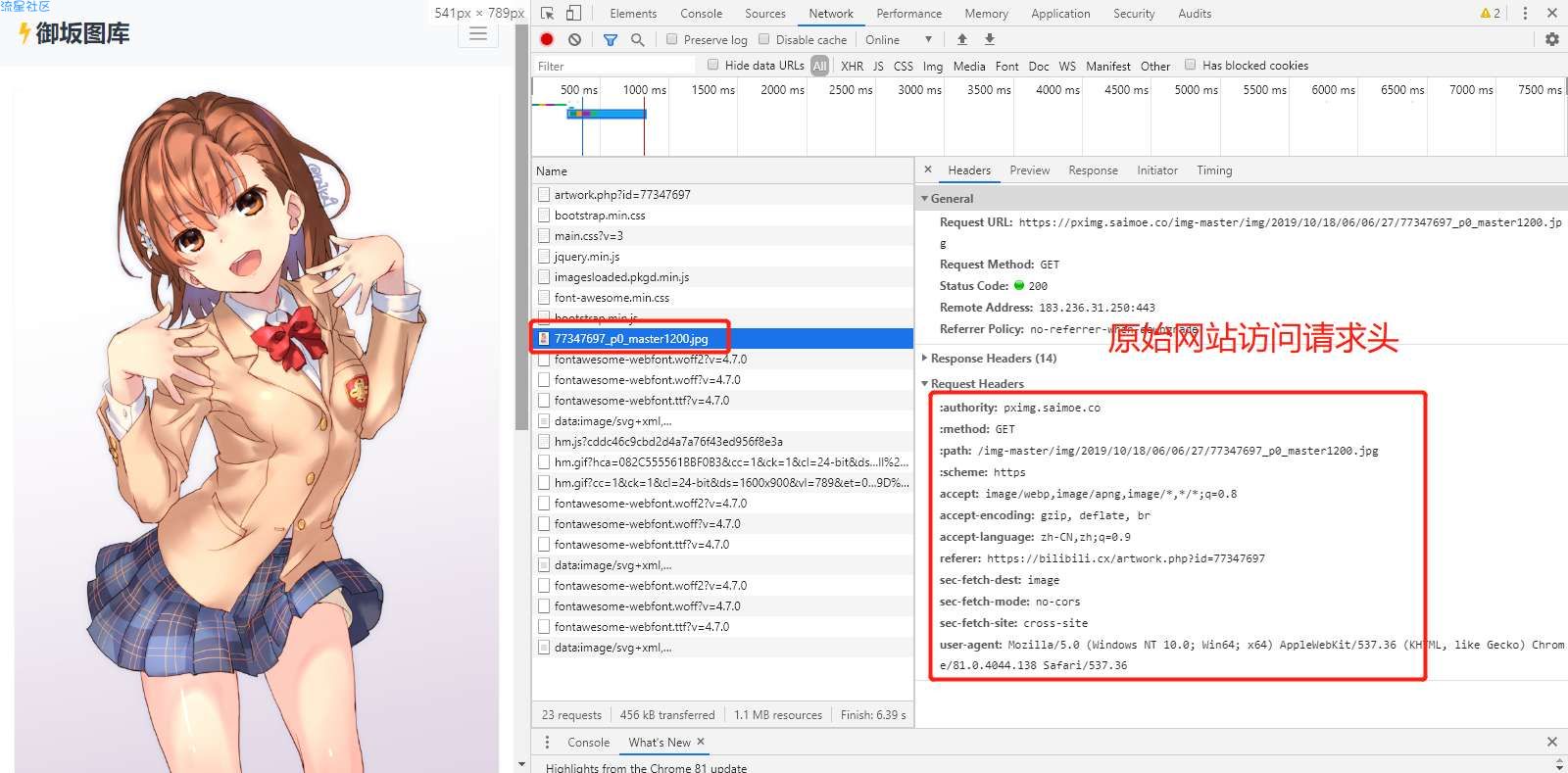
怀疑是请求头中加入了反爬策略,经过测试后发现请求头中必须有Host与referer字段
测试加上请求头后访问正常
回复列表
-
内容加载中...
说点什么...
 返回首页
返回首页
 编程源码
编程源码


