抓取淘宝商品信息爬字

目标:获取淘宝搜索页面信息,爬取商品的名称和价格
方法:淘宝的搜索接口
翻页处理
库:requests
对比网址:
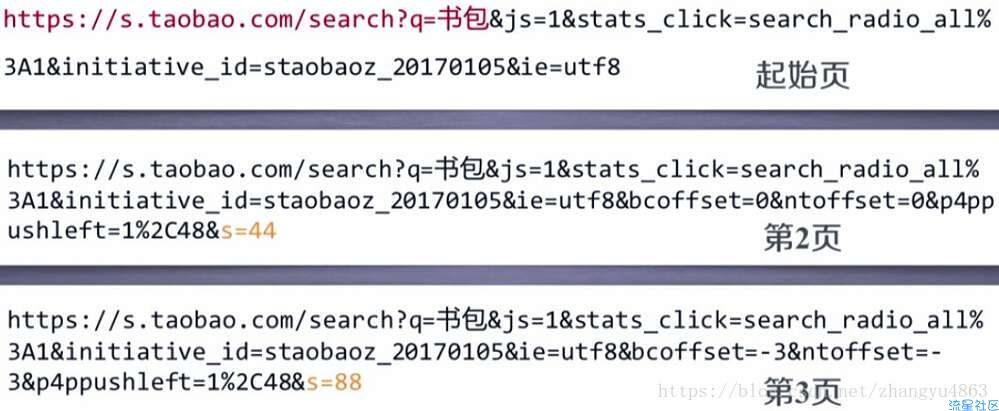
起始页
第二页 s=44
第三页 s=88
得到 第n页是s=(n-1)*44
5条回复 |
最后回复于2020-7-5
淘宝网站的robots协议(一般网站的robots协议约定放在网站的主目录下的/robots.txt中)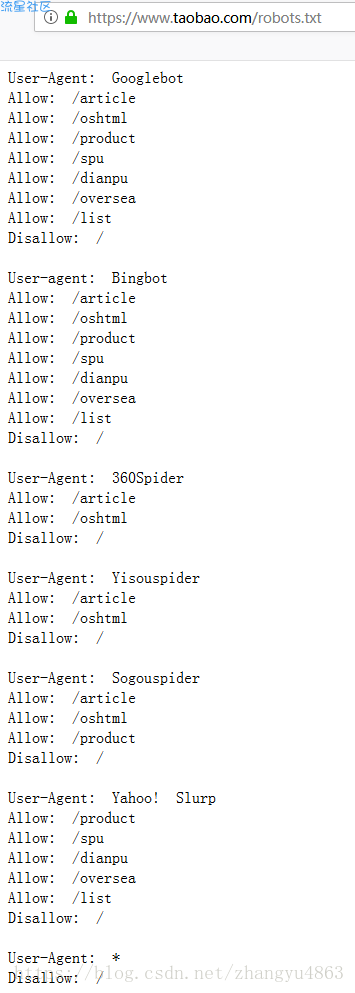
回复列表
-

内容加载中...
说点什么...
可以看出爬虫不得对淘宝的搜索页面进行爬取(爬取速度就像人类的速度则是允许的)
User-agent 用户(叫爬虫种类或者名称)
Allow 允许爬取的目录
Disallow 不允许爬取的目录
User-agent 用户(叫爬虫种类或者名称)
Allow 允许爬取的目录
Disallow 不允许爬取的目录
回复列表
-
内容加载中...
说点什么...
程序结构:
1.提交商品搜索请求,循环获得页面
2.从每个页面中提取商品的名称和价格信息
3.打印输出
以搜索鞋为例: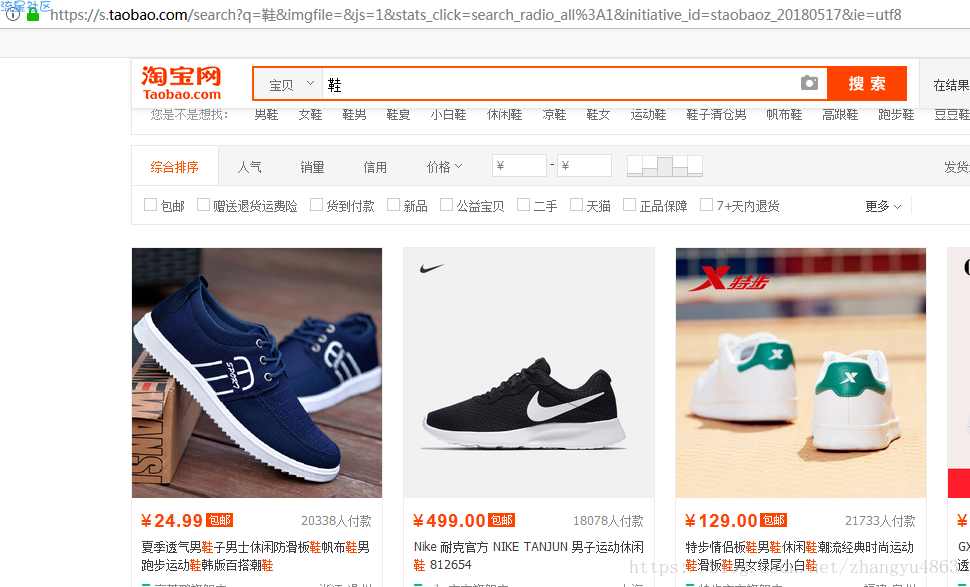
1.提交商品搜索请求,循环获得页面
2.从每个页面中提取商品的名称和价格信息
3.打印输出
以搜索鞋为例:
回复列表
-
内容加载中...
说点什么...
结论:raw_title和view_price分别对应名称和价格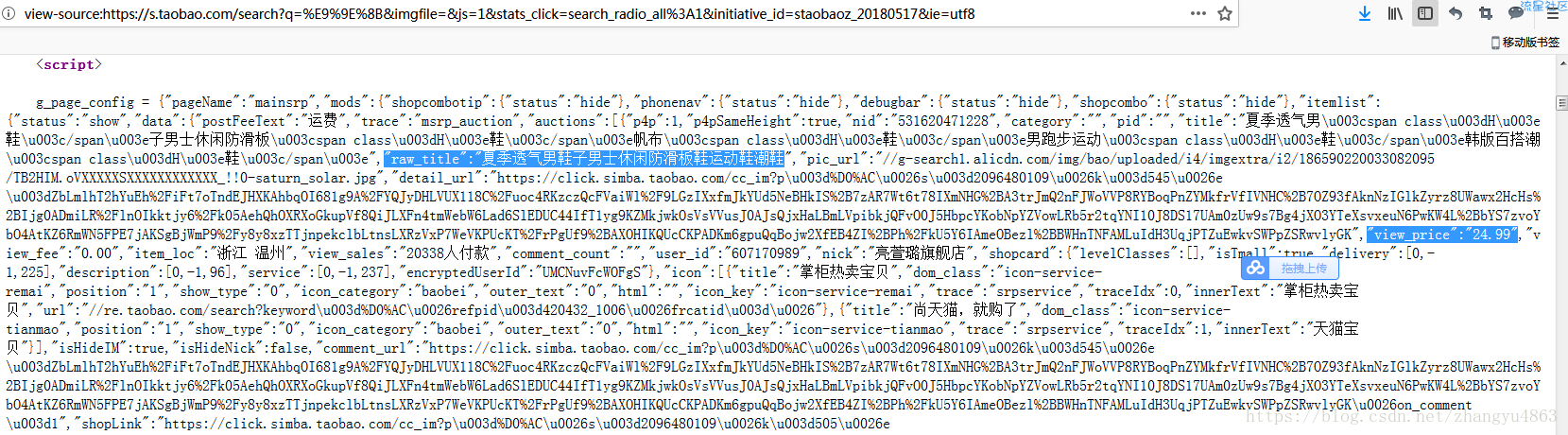
回复列表
-
内容加载中...
说点什么...
代码:
# -*- coding:utf-8 -*- # 解决python不兼容中文
# 加载requests库
import requests
# 加载正则表达式模块
import re
# 爬取网页内容模块
def get_html_text(url): # 获取要访问的网址
try:
r = requests.get(url, timeout=30) # 把爬取后的内容赋给r,等待时间对多30秒
r.raise_for_status() # 爬取网页时返回的状态码
r.encoding = r.apparent_encoding # 把从内容中分析的编码方式赋给从HTTP header中猜测的编码方式
return r.text # 返回爬取网页后的文本
except RuntimeError: # 一般超时错误
return "" # 函数结束返回
# 从爬取网页的文本内容中提取有价值信息
def parse_page(self, html): # 接收
try:
find_price = re.findall(r'"view_price":"[d.]*"', html)
find_title = re.findall(r'"raw_title":".*?"', html)
for i in range(len(find_price)):
price = eval(find_price[i].split(':')[1])
title = eval(find_title[i].split(':')[1])
self.append([price, title])
except RuntimeError: # 一般超时错误
print()
# 打印提取后的数据
def print_goods_list(data):
headline = "{:4} {:8} {:16}"
print(headline.format("序号", "价格", "商品名称"))
count = 0
for i in data:
count = count + 1
print(headline.format(count, i[0], i[1]))
# 主函数
def main():
search_text = '鞋' # 设置在淘宝搜索的内容
depth = 3 # 设置爬取深度为3页
start_url = '[hide]https://s.taobao.com/search?q=[/hide]
' + search_text
information_list = []
for i in range(depth):
try:
url = start_url + '$s=' + str(44*i)
html = get_html_text(url)
parse_page(information_list, html)
except RuntimeError: # 一般超时错误
continue
print_goods_list(information_list)
main()
# -*- coding:utf-8 -*- # 解决python不兼容中文
# 加载requests库
import requests
# 加载正则表达式模块
import re
# 爬取网页内容模块
def get_html_text(url): # 获取要访问的网址
try:
r = requests.get(url, timeout=30) # 把爬取后的内容赋给r,等待时间对多30秒
r.raise_for_status() # 爬取网页时返回的状态码
r.encoding = r.apparent_encoding # 把从内容中分析的编码方式赋给从HTTP header中猜测的编码方式
return r.text # 返回爬取网页后的文本
except RuntimeError: # 一般超时错误
return "" # 函数结束返回
# 从爬取网页的文本内容中提取有价值信息
def parse_page(self, html): # 接收
try:
find_price = re.findall(r'"view_price":"[d.]*"', html)
find_title = re.findall(r'"raw_title":".*?"', html)
for i in range(len(find_price)):
price = eval(find_price[i].split(':')[1])
title = eval(find_title[i].split(':')[1])
self.append([price, title])
except RuntimeError: # 一般超时错误
print()
# 打印提取后的数据
def print_goods_list(data):
headline = "{:4} {:8} {:16}"
print(headline.format("序号", "价格", "商品名称"))
count = 0
for i in data:
count = count + 1
print(headline.format(count, i[0], i[1]))
# 主函数
def main():
search_text = '鞋' # 设置在淘宝搜索的内容
depth = 3 # 设置爬取深度为3页
start_url = '[hide]https://s.taobao.com/search?q=[/hide]
' + search_text
information_list = []
for i in range(depth):
try:
url = start_url + '$s=' + str(44*i)
html = get_html_text(url)
parse_page(information_list, html)
except RuntimeError: # 一般超时错误
continue
print_goods_list(information_list)
main()
回复列表
-
内容加载中...
说点什么...
 返回首页
返回首页
 编程源码
编程源码


